
Digital Archaeology for Engineering Leaders 🧱
Tech Due Diligence — When You Inherit an R&D Org You Don’t Know

How to Run Tech Due Diligence When You Land in a Team You Don’t Know ⚠️
So here’s the situation.
You’ve just inherited an R&D team in another country. You don’t speak the language — of the code or the people. The architecture diagram is from 2018. There are 42 GitHub repositories, and no one remembers what half of them do. The team shrugs and says things like, “Oh yeah, that microservice kinda just works — don’t touch it.”
Congrats! You’re now the captain of this spaceship. 🚀
In this context, tech due diligence isn’t a checkbox exercise. It’s detective work 🕵🏼♀️. It’s anthropology. It’s digital archaeology. You’re trying to figure out what’s been built, how it works (or doesn’t), who understands what, and where the landmines are buried — all while smiling in team meetings and pretending like you’re not silently panicking.

I’ve been there. This post is the playbook I wish someone had handed me on Day 1. It’s how I start making sense of the mess, build trust with the team, improve the developer experience, and move the org forward — without rewriting everything or accidentally nuking morale.
Start with the People, Not the Code 👩🏼💻
When you step into a new team, especially in unfamiliar territory, the instinct to open GitHub and start poking around is strong. But resist it! The code can wait. The real story — and the real leverage — starts with the people. Spend time with the team at all levels, not just leads or architects. Talk to the developers who’ve been around forever, and especially the ones who’ve just joined. Chat with QA, DevOps, even the person who maintains the build scripts but sits on a different Slack channel.
Ask how they feel about the system. What’s painful? What’s delightful? What’s been broken so long they stopped noticing? These stories give you a visceral sense of how the system operates in practice. They also reveal early insights about morale, confidence, and team health. People will hint at the parts of the system they avoid or whisper about the service that “just works” but no one dares to touch. These aren’t just anecdotes — they’re early indicators of DevEx friction points.
What’s more, starting with conversations helps build psychological safety. Start also discussing more personal matters. What they like? What are their career aspirations? It tells the team you’re listening, not judging. You’re not here to bulldoze — you’re here to understand. That shift in posture can unlock collaboration you’ll need later when you propose change.
Build a Knowledge Map and Capability View 🗺️
Once you’ve had enough conversations to spot themes, begin stitching them together into a working map of how knowledge and capability are distributed. This isn’t about charting a perfect org diagram or building a Notion wiki just yet. Instead, you’re trying to answer a few practical questions: Who understands what? Who are the go-to folks for particular parts of the system? Where do we have redundancy — and where do we have fragile, single-person dependencies?
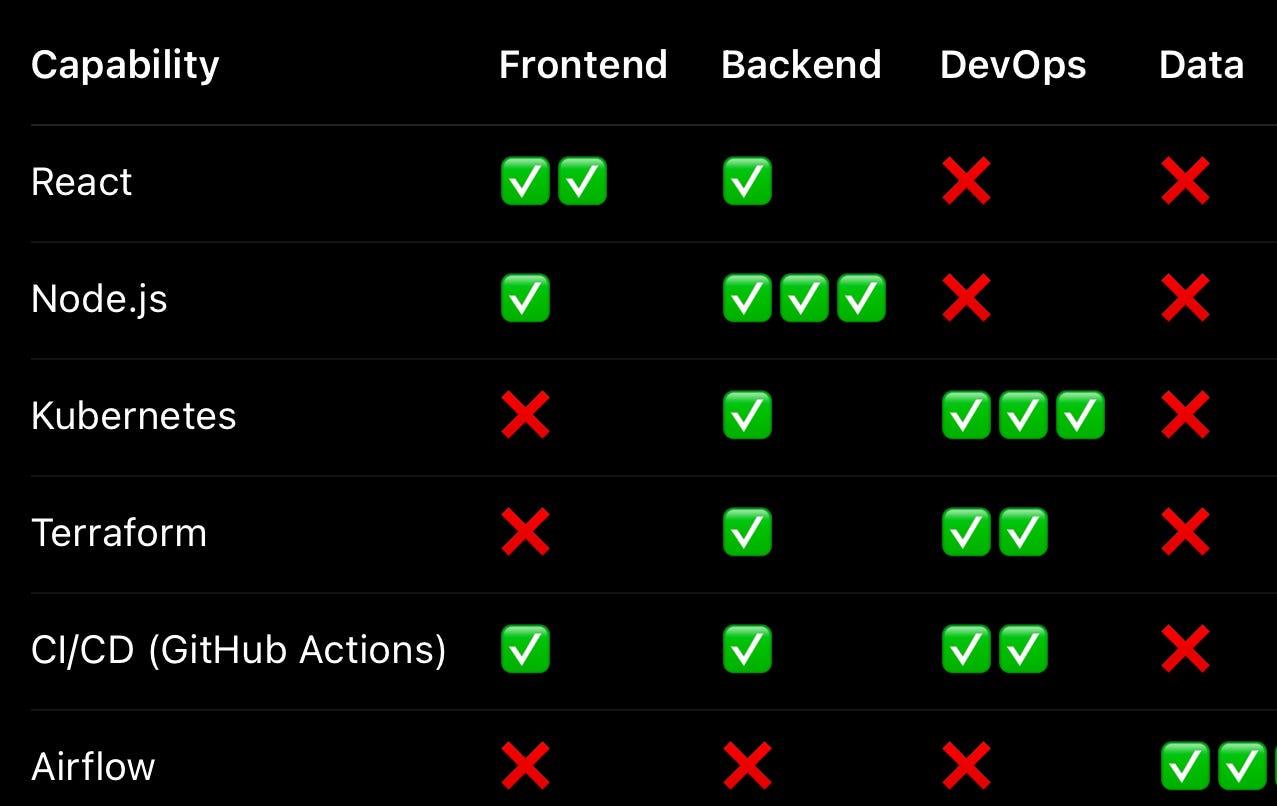
This kind of map often starts with post-it notes or a whiteboard (virtual or physical). You’re mapping code ownership, operational expertise, and institutional memory — and identifying where the gaps are. Often, what emerges is a patchwork: certain repos no one claims, tools that only one engineer knows how to maintain, and pipelines everyone complains about but no one feels responsible for.
These gaps are not just technical risks; they’re DevEx liabilities. When developers don’t know who to ask or lack confidence that anyone understands a service deeply, it slows down progress and makes change feel dangerous. Building this knowledge map gives you the foundation to improve onboarding, reduce key-person risk, and surface the hidden work that keeps everything afloat.
Try to Understand What’s Actually There 😳
Now that you’ve talked to people and started piecing together how things are connected, it’s time to dig into the repos. Ask for architecture diagrams and other formal docs — even if they’re out of date. What matters isn’t precision but intention. These diagrams tell you how the system was supposed to be structured, and that context is invaluable.
From there, go into GitHub and start exploring. Look at which repos are active, which ones have recent commits, and which ones haven’t been touched in months (or years). Try to match code with deployed services. Often, you’ll find orphaned repos still consuming cloud resources, contributing nothing but cost and confusion. Document what you can, and pay attention to what isn’t documented — those are often the parts no one wants to deal with.
At this stage, you’re not trying to do a full technical review. You’re orienting yourself — mapping terrain, not optimizing it. You’re answering, “What’s actually live? What’s running? And who’s touching what?” Gaps in clarity here directly affect DevEx: if engineers don’t know whether a repo is active, or if modifying a service feels risky, it slows down everything else.
Run Static Analysis — and Not Just for the Score 🪜
Now that you have a sense of what’s running, it’s time to go deeper. Static analysis tools like SonarQube, CodeClimate, or DeepSource can help you get a quick view into maintainability, complexity, duplication, and code smells. You don’t need to treat these scores as gospel — but they give you a consistent way to compare services and spot outliers.
Focus on where the rough edges are. You’re looking for clusters of technical debt, but more importantly, for signs of inconsistent engineering standards. Are there pockets of clean, well-tested code? Are there entire services riddled with warnings and skipped tests? These differences often reflect not just technical maturity, but how much love and attention each part of the system receives.
Healthy codebases improve confidence, and confidence improves velocity. Developers are more willing to ship when they trust what they’re working with. Static analysis surfaces the invisible factors that make engineering feel slow or stressful — and fixing them is often the fastest path to improving DevEx across the board.
Code Coverage Tells a Story 🔎
Code coverage isn’t about chasing arbitrary thresholds. It’s about understanding how safe it feels to make changes. A service with robust test coverage and stable builds is one that developers feel comfortable evolving. On the flip side, a codebase limping along with 12% test coverage — and a reputation for breaking in production — breeds fear. That fear changes how teams behave.
Developers avoid touching fragile code. They invent workarounds. They silently accumulate risk. Low coverage becomes a tax on innovation and experimentation. It’s not just a testing issue — it’s a trust issue.
So coverage data becomes a proxy for psychological safety. You’re not aiming for perfection, but for enough confidence that changes don’t feel like walking on glass. That confidence is a cornerstone of a healthy DevEx environment.
Treat the Code Like a Crime Scene 🔪
This is where things get really revealing. Instead of reading the code, start reading its history. Dig into Git logs and analyze how files evolve over time. Look for patterns — which modules are changed most frequently? Which ones have the largest pull requests? Are there hotspots where every fix requires multiple reworks?
This kind of forensic analysis helps you pinpoint where technical debt lives, but also where cognitive load is highest. One file with hundreds of commits, all made by the same person? That’s a risk disguised as a hero. Long-lived PRs with high churn? That’s complexity bleeding into delivery.
Tornhill’s “Your Code as a Crime Scene” nails this perspective. You’re not looking for bad code — you’re looking for fragile process, silent friction, and hidden risk. All of which affect how developers work day to day. When the codebase stops surprising you, that’s when DevEx improves.
Secrets and Dependencies Will Surprise You 🤐
Security is not a project you check off — it’s a living process. And left unchecked, entropy always wins. Run scans for exposed secrets with tools like Gitleaks or TruffleHog. Audit dependencies using Snyk or your package manager’s built-in tools. Yes, the results will be messy. That’s expected.
But every exposed secret or outdated library is an operational risk. Worse, it’s often a symptom of broken process — secrets committed out of convenience, packages left behind because the upgrade path was painful.
Cleaning this up is about more than just hardening security. It’s about reducing stress, increasing flow, and giving your engineers more headspace. That’s the kind of change that meaningfully improves DevEx.
Walk the Pipeline 🚶🏻
Next, follow the delivery journey. Pick a real change — ideally a bug fix or small feature — and trace it from the moment code is committed to when it lands in production. What’s fast? What’s slow? Where does it break?
Talk to the team as you do this. Ask what frustrates them most about the build process. Which tests are flaky? How long does it take to get a review? How often do deploys fail for mysterious reasons? These aren’t just process hiccups — they’re invisible forces dragging down productivity and morale.
A slow or unreliable CI/CD pipeline is a hidden DevEx killer. It turns shipping into a gamble. Streamlining this journey is one of the highest-leverage improvements you can make, because it touches every engineer, every day.
Track How the System Behaves, Not Just What It Contains 🕹️
At this point, you’ve looked at the system’s structure. Now look at how it behaves.
DORA metrics give you a clean, actionable view into how well your engineering org is functioning. How fast do you ship? How often do things break? How quickly do you recover?
You can extract this from GitHub and CI/CD data, or plug in tools like LinearB or getDX. Either way, don’t obsess over the numbers — focus on what’s slowing the team down. Long PR review times, brittle integration tests, unclear ownership — these will show up as red flags.
When teams operate in a high-trust, low-friction environment, these metrics trend in the right direction. When they don’t, it’s often a reflection of systemic issues that make good DevEx impossible.
Understand the Stack with a Tech Radar 🧭
Once you’ve got a grip on how the system works, turn your attention to what it’s made of. Build a tech radar to capture the tools, frameworks, libraries, and platforms in use — and more importantly, their status. Is this framework being actively developed? Is that database still serving production, or just a leftover experiment?

A tech radar helps you spot unnecessary sprawl, highlight deprecated tools, and identify where the stack is aging in place. It’s also a fantastic way to empower developers — giving them clarity on which tools are supported and which ones are on the way out.
Good tech choices reduce friction. Bad or ambiguous ones increase it. Reducing stack chaos is a gift to DevEx.
Synthesize with a Tech Health Radar 🏥
Now it’s time to pull everything together. A Tech Health Radar is your way of showing — visually and honestly — where things hurt.
You’re capturing reality, not presenting a polished status report. Maybe onboarding is slow. Maybe test failures are random. Maybe no one understands how the deployment system actually works. That’s okay. What matters is surfacing those issues clearly and consistently.
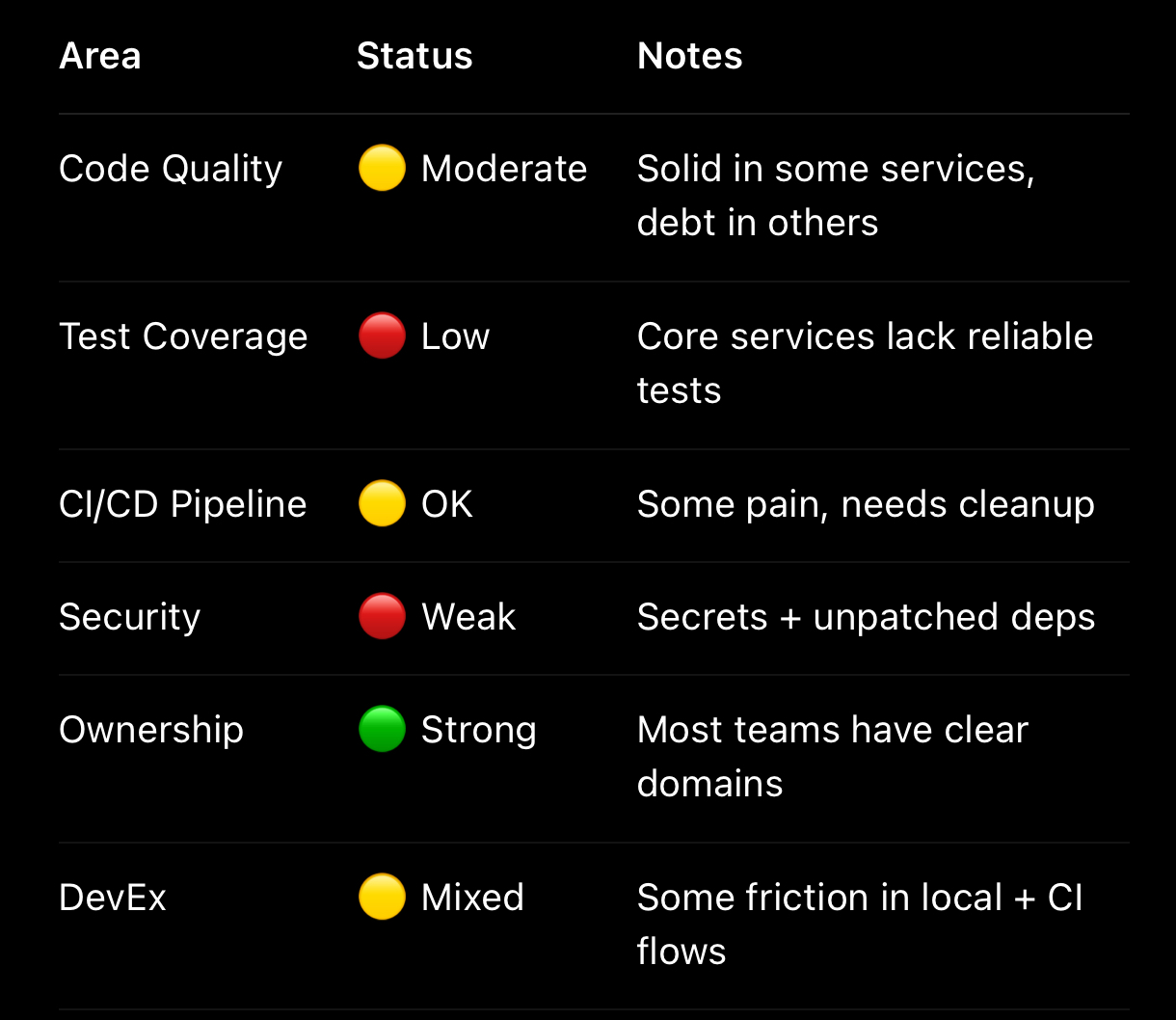
This radar becomes your shared map. It helps you have better conversations with leadership, make smarter bets with the team, and prioritize invisible work that’s often deprioritized. If you want to advocate for better DevEx, this is your tool.
Drive Change with SMART OKRs 🎯
Finally, once you understand the system, you can start to improve it — deliberately. That means setting goals that are specific, measurable, and connected to real pain.
Forget vague promises to “clean up tech debt.” Instead, pick clear outcomes tied to your radar. Improve test reliability. Raise confidence in deployment. Reduce security exposure. Shorten feedback loops.
🎯Objective: Improve Code Quality and Security (Q3 2025)
We want to move from reactive cleanups to a proactive security and quality posture — with each KR shifting a measurable RAG status.
👉🏻KR1: Scan 100% of active repositories for hardcoded secrets by July 31, and remove any found
Red: No scanning in place, secrets show up in prod occasionally
Amber: Manual scanning in a few repos, issues caught late
Green: Automated scanning across all active repos, zero hardcoded secrets in main branches
✅ Needle: Currently Amber → Targeting Green
👉🏻KR2: Increase average SonarQube maintainability rating from B to A across the top 10 repos by September 15
Red: C or below — code is hard to understand, maintain, or extend
Amber: B — maintainable, but technical debt is growing
Green: A — high readability, clean complexity, reduced bugs over time
✅ Needle: Currently Amber → Targeting Green
👉🏻KR3: Reduce the number of critical CVEs in production dependencies by 90% by end of Q3
Red: Multiple known CVEs in production, unmanaged
Amber: CVEs tracked but patching is ad hoc or lagging
Green: Near-zero critical CVEs, updates automated or prioritized
✅ Needle: Currently Red → Targeting Green
🎯 Objective: Increase Delivery Confidence and Developer Trust (Q3 2025)
Reduce frustration, flakiness, and failed builds. Get devs back to trusting the system — and shipping with confidence.
👉🏻KR1: Raise unit test coverage to at least 80% for the top 3 services (by usage) by August 31
Red: Coverage <50%, bugs often hit prod
Amber: 50–79%, tests exist but don’t fully cover logic
Green: 80%+, meaningful coverage with reduced regression issues
✅ Needle: Currently Amber → Targeting Green
👉🏻KR2: Optimize CI pipeline to ensure average build time is under 10 minutes for all services by September 15
Red: Builds regularly take 15+ minutes, devs avoid pushing
Amber: Inconsistent times, some services optimized, some lag
Green: Sub-10-minute builds across the board, fast feedback loop
✅ Needle: Currently Red → Targeting Green
👉🏻KR3: Improve CI/CD reliability to >90% successful runs on first try by quarter end
Red: Frequent flaky failures, retries required
Amber: 70–89% success, some systems solid, others brittle
Green: 90%+ success on first run, devs confident in pipeline
✅ Needle: Currently Amber → Targeting Green
These OKRs aren’t about making your slide deck look good. They’re about aligning leadership with engineering — and showing the team that progress is real, visible, and worth investing in.
The TL;DR
When you inherit an unfamiliar R&D org, don’t start by rewriting code. Start by listening. Map the knowledge. Understand what’s running. Pay attention to behavior, not just structure.
Use tools like SonarQube, Git history, DORA metrics, and yes, “Your Code as a Crime Scene” to surface what’s really going on. Then fix the right things — in the right order — with buy-in from the team.
And always remember: better developer experience isn’t a luxury. It’s the foundation for sustainable, joyful, high-performing engineering.
You’ve got this. Now go tame that jungle and maybe bring some extra coffee ☕️.
This is a very nice one! 👌